
Recently, we've seen content platforms like YouTube implement video chapters to make their content more digestable for viewers.
With the rise of generative AI, we thought it'd be useful to build a workflow to auto-generate these video chapters using public models including OpenAI's Whisper, GPT-3, and nltk's Text Tiling implementation. In this blog post, we'll dive into the specifics of our workflow and how it works.
If you'd like to try it for yourself or integrate into your own app, try it on Sieve by clicking the button below. Keep reading if you'd like to learn about how it works.
Audio Transcription
Speech-to-text models have been around for more than a few years, but none rival OpenAI's Whisper model in accuracy & speed. With OpenAI's Whisper model running on Sieve, we're able to generate an accurate transcript of a 15 minute video in less than a minute.
Here's a quick breakdown how the Whisper model works:
- Preprocessing: The input audio is first converted to a spectrogram, which represents the frequencies present in the audio over time.
- Encoding: The spectrogram is then passed through a convolutional neural network (CNN) that processes the audio and generates a set of encodings that help with future steps.
- Generation: The encoding is used as input to a decoder, which generates the output text word by word, conditioned on the previously generated words. The decoder uses a technique called beam search to generate multiple candidate outputs and selects the most likely output based on a scoring function that takes into account both the model's confidence in the generated text and the coherence and relevance of the generated text.
Text Segmentation
To be effective in generating chapters from video, we need some method of segmenting different topics. In our workflow, we use the Natural Language Python Toolkit (nltk) and its implementation of Text Tiling.
Text Tiling is a technique for text segmentation that identifies major topics or themes in a document and divides the text into coherent segments. Here's a brief overview of how Text Tiling works:
- Preprocessing: The input text is first tokenized into individual words and stop words (common words such as "the," "a," and "and") are removed. Words are also reduced to their base form in a process called lemmatization to reduce the number of unique words.
- Similarity calculation: Next, adjacent blocks of text are compared using a sliding window approach. A sliding window of fixed size is moved across the text, and the cosine similarity between the term frequency vectors of adjacent windows is calculated. The term frequency vector represents the frequency of each word in the text segment.
- Segmentation: The text is then segmented into blocks using a threshold score. Blocks of text with similarity scores above the threshold are grouped together, while blocks with scores below the threshold are considered to represent a different topic or theme and are assigned to a new segment.
GPT-3 Prompting
After we have our transcript segmented into topics, we can prompt GPT-3 to generate chapter headings.
For those unfamiliar, GPT-3 is a language model that uses a deep neural network with a transformer architecture to generate natural language text. It is trained on a massive corpus of text using unsupervised learning techniques, which allows it to generate coherent and contextually relevant text in response to a given prompt or task.
However, GPT-3 does have a limitation in the number of tokens it can take in as its prompt, which means we can't simply pass in a long transcript and generate chapter headings.
To work around this, we prompt GPT-3 twice:
- First, we generate chapter headings for each section by itself
- Then, we prompt GPT-3 to consolidate all chapter headings and remove any unnecessary ones
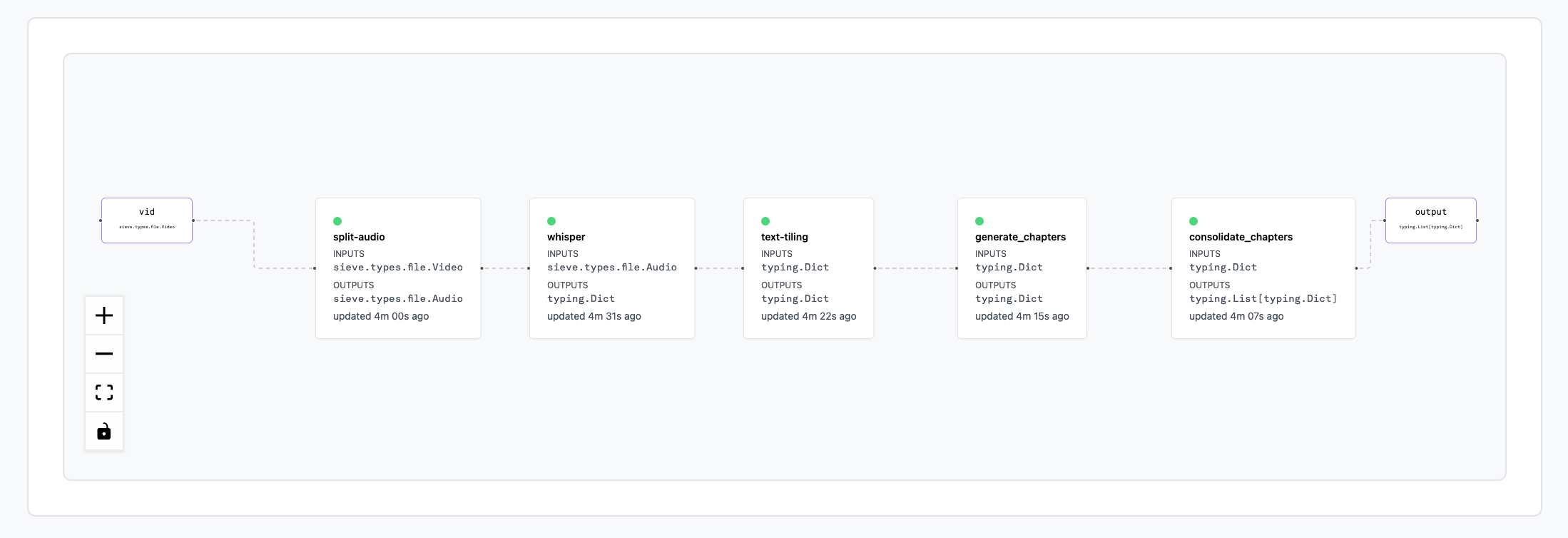
Our final workflow
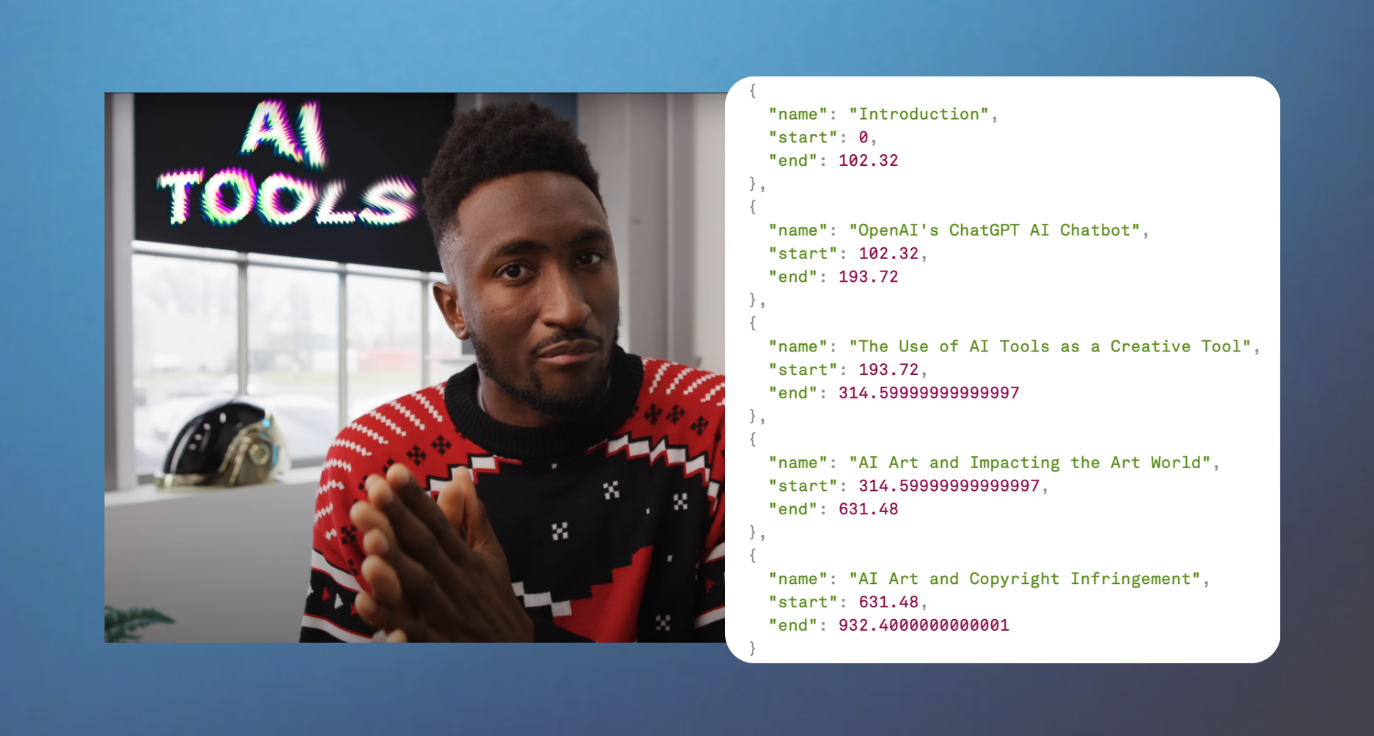
We ran our workflow on this sample video of popular YouTuber, MKBHD, talking about AI and in less than a minute, we have chapter headings!
[
{
"name": "Introduction",
"start": 0,
"end": 102.32
},
{
"name": "OpenAI's ChatGPT AI Chatbot",
"start": 102.32,
"end": 193.72
},
{
"name": "The Use of AI Tools as a Creative Tool",
"start": 193.72,
"end": 314.59999999999997
},
{
"name": "AI Art and Impacting the Art World",
"start": 314.59999999999997,
"end": 631.48
},
{
"name": "AI Art and Copyright Infringement",
"start": 631.48,
"end": 932.4000000000001
}
]What next?
To start generating your own chapter headings for custom videos or integrate this into your app, you can run our template workflow from our dashboard. We offer $20 of credit, so you can get started right away.
In addition to pre-built building blocks and models, Sieve deploys your custom models at scale, so you don't have to worry about infra and can focus on building your video AI features fast. If you have any models you would love to see on Sieve's platform or have any questions about custom use cases, please don't hesitate to reach out.