

Active speaker detection (ASD) is the task of detecting who is speaking in a visual scene of one or more speakers. The example below is best at illustrating what this actually means — the box is green when the person is speaking and red when they’re not.
Detecting active speakers in video content is useful across applications like content creation and video conferencing. Products like Opus Clip have blown up by building simple ways for users to take long-form content and automatically turn them into short, bite-sized clips that are ready to post on social platforms like TikTok. This means finding the most interesting moments and then “auto-editing” the content into a different aspect ratio, which can be done automatically using a combination of speaker detection and object detection models.

These products are great, but what you’ll typically notice is that they’re slow because the underlying models used, such as TalkNet, are incredibly slow. The original implementation for example would take ~3.5 mins to process that 1.5 minute clip above.
Digging deeper into the implementation of these models, we’ll find that really they are pipelines that combine multiple functions & models together. There are likely ways to speed things up but this means:
- setting up a service that orchestrates multiple AI models
- setting up various AI models as different deployments on GPUs
- communicating with AI models running on completely different machines
- scaling up and down GPU machines on-demand without hitting rate-limit or other snag
- managing job results and triggering new jobs based on them
In this blog post, we’ll go over how models like TalkNet work and how we built an active speaker detection solution which performs ~90% faster than other solutions (hint: we used Sieve!).
The Task and Varying Approaches
As suggested in the TalkNet paper, the active speaker detection task comes down to three things:
- Does the audio of interest belong to human voice?
- Are the lips of the person of interest moving?
- If the above are true, is the voice synchronized with the lip movement?
The most basic of approaches involves looking at just the second point above. Libraries like mediapipe have made it both cheap and easy to extract detailed face landmarks (point predicted for varying portions of a person’s face). The natural thing to do with this information in our case would be to simply take these coordinates, take the size of the face, and see if these points move past some threshold in relation to the size of the face over a given period of time.
While this is a sound approach to try at first, there are a lot of simple cases where this breaks down. For example, what if people eating or moving the mouth at a time when they aren’t actually speaking? To that end, it becomes obvious that we need to use other features we have available to us.
TalkNet
TalkNet-ASD is the easiest-to-use speaker detection model in recent years that actually works well. Other models that have come out more recently claim better results, but are either much more compute-intensive to run, don’t work with the code published on them, or produce noisier results that may have overfit on the benchmark datasets. For example, we tried using models like light-asd which claimed better results but turned out to be much noiser and sporadic in the scores it returned. On the other hand SPELL+ (or GraViT) was virtually unrunnable, impossible to setup, and slow overall.
The core realization in the TalkNet paper was that it’s pretty easy for us as humans to know whether someone is speaking due to the longer temporal context we have. As a thought experiment, would it be easier to detect who’s actively speaking in a 200ms video or a 2 second video? This visual from the paper illustrates why it’s likely easier given a longer clip.
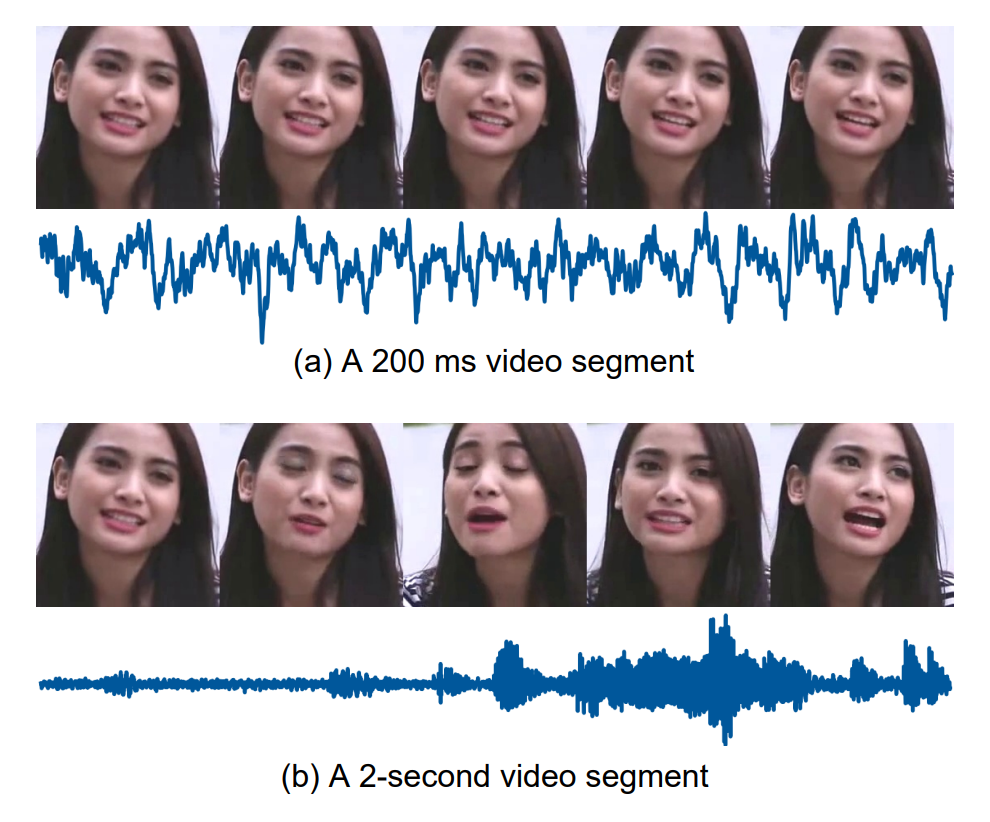
TalkNet was able to outperform previous methods by using both short-term and long-term temporal features to accurately identify active speakers. They do this using:
- a feature representation network to capture the long-term temporal context from audio and visual cues.
- a backend classifier network that employs audio-visual cross-attention, and self-attention to learn the audiovisual inter-modality interaction.
- an effective audio augmentation technique to improve the noise-robustness of the model.
This then fits into a broader pipeline that does the following
- Extract video frames and audio from original file
- Cut video into scenes
- Detect and track faces within each scene
- Pass each tracked face along with the corresponding audio into the core speaker detection model
- Return results as a property of each tracked face
Our Implementation
Optimizing TalkNet
While we loved the original implementation of TalkNet found here, we found it to be pretty slow. After investigating the code, we noticed that most of the time spend was on pre-processing operations before the actual speaker model was run. We improved efficiency of this core pre-processing by storing video frames in memory when possible, and removing inefficiencies in how these frames were fed into a face detection model.
It depends video to video but we found that this video for example took 186.1s to process with the original implementation and instead now takes 97s (on a V100 GPU). That’s almost a 50% reduction in processing time! Just from a little improvement in pre-processing.
Parallelization
While this is great, we weren’t satisfied and wanted to further optimize. We noticed that still, a bulk of our time was being spent on the face detection being done prior to the speaker detection model running, along with other post-processing steps. This is where Sieve came in.
Sieve provides an easy way for teams to combine AI models with custom logic to build end applications. In this particular case, we’ll go over combining the TalkNet and YOLO functions available on Sieve — and how we parallelize the use of the models across a lot of data to make our videos process faster.
With Sieve, running YOLO on a video for example is as simple as the following.
import sieve
yolov8 = sieve.function.get("sieve/yolov8")
video = sieve.File(path="./some_path.mp4")
output = yolov8.run(video)
print(output)You could easily then parallelize across video chunks by instead this.
import sieve
yolov8 = sieve.function.get("sieve/yolov8")
video = sieve.File(path="./some_path.mp4")
video_last_frame = 10000
frame_interval = 300
outputs = []
for i in range(0, video_last_frame, frame_interval):
start_frame = i
end_frame = i + frame_interval
outputs.append(
yolov8.push(
video,
start_frame = start_frame,
end_frame = end_frame
)
)
for output in outputs:
print(output.result())And so our implementation swaps out the original S3FD face detection model used in TalkNet for a finetuned version of YOLOv8 that runs faster and in parallel. Specifically, we process chunks on video (300 frames or so) separately and feed those results into the speaker detection model as the face detection completes. Below is an example of how we’d use these models together.
import sieve
yolov8 = sieve.function.get("sieve/yolov8")
talknet = sieve.function.get("sieve/talknet-asd")
video = sieve.File(path="./some_path.mp4")
face_outputs = yolov8.run(video, models="yolov8l-face")
# convert YOLO outputs to a format that TalkNet takes in
string_outputs = transform(face_outputs)
speaker_results = talknet.run(video, face_boxes=string_outputs)This brings the processing time on the same video down to ~31s. That’s almost 70% faster than our optimized version of TalkNet and almost 90% faster than the original TalkNet implementation! And it scales with your demand, ready for production-use :)
Getting Started Yourself
I may be a bit biased because I work at Sieve but we think our platform is the best way to implement and use this sort of stuff, especially because it’s using multiple models. You can find the source-available implementation to this here, and you can try it yourself here on Sieve. We also encourage you to check out the functions we used as building blocks like yolov8 and talknet.
If you’re thinking about this kind of capability in your application, please reach out to us with feedback and questions. The best way to do this is by joining our Discord community! We’re always looking for honest feedback on work like this.