

What is AI Lip Syncing?
Realistic overlaying of audio onto a single-speaker (or “talking-head”) video – also known as video lip syncing, retalking, or dubbing – is a powerful feature of Generative AI that allows for videos to be edited with slightly different audio, dubbed into different languages, or even create hilarious TikToks. Here's a fun one we made given the present OpenAI / Microsoft saga:
In today’s age of targeted media content, changing videos slightly to fit a specific demographic can allow companies to have a higher impact on different niche audiences. One recent example of this was when Cadbury put out an ad campaign featuring famous Indian movie star Shah Rukh Khan, which realistically dubbed his voice to speak many different languages.
What Are the Major Frameworks for AI Lip Syncing?
LipGAN, Wav2Lip, and Video ReTalking all take different approaches to building a model or set of models to yield convincing results for lip syncing, yet they have a few issues preventing them from being deployed to production.
LipGAN and Wav2Lip are somewhat unstable in several scenarios, making the lips move in unnatural ways and not blending them properly to match the expression of the rest of the face. Video ReTalking is much better at making the lips look natural and realistic. However, it is quite slow, with the naive solution taking up to 1 minute to process a single second of audio and video. It also degrades the quality of the entire video, producing small artifacts and introducing some graininess. In addition, it can fail with lower-quality input data, which we often encounter in production scenarios.
Introducing SieveSync
Sieve’s new solution for video lip syncing has a suite of different model and enhancement options. It offers several backends. Newly-launched SieveSync leverages an alignment technique developed in-house with optimized MuseTalk and LivePortrait for better sync with the audio and faster inference. Other options include MuseTalk – which couples the MuseTalk model with an optional addition of CodeFormer to sync the lips in the driver video/image with the provided audio and restore the face – and Video ReTalking, which leverages the namesake model with GPEN and GFPGAN (generative face restoration algorithms that allow the mouth and teeth to look more realistic).
SieveSync builds on knowledge gained from earlier work modifying the Video ReTalking repository to address some of its flaws in terms of speed and quality.
Background: Video Retalking
For background, here is an overview of the original implementation in the Video ReTalking repository.
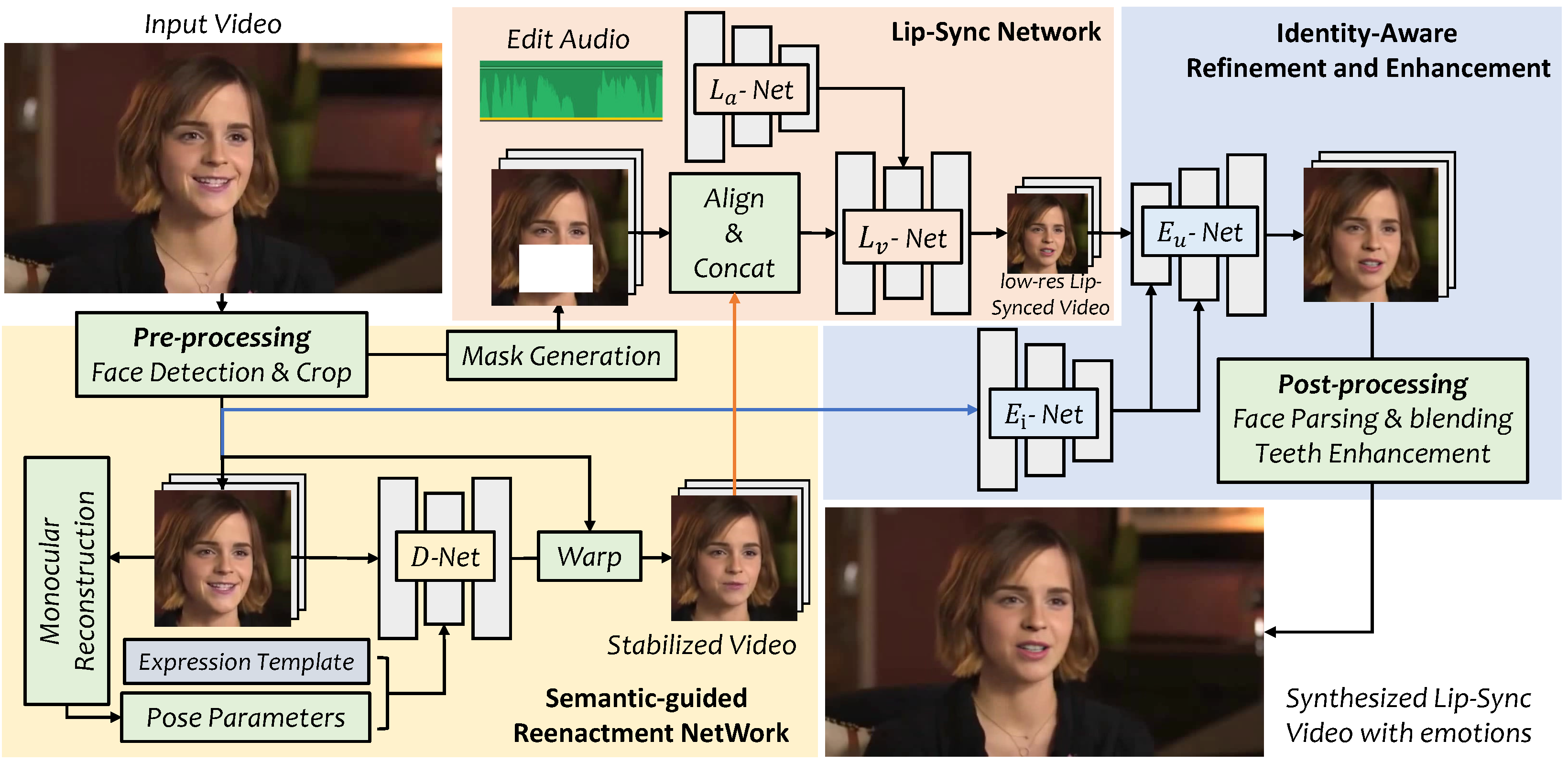
First, we extract facial landmarks from the original video. Next, we stabilize each frame of the original video with an expression using a model known as D-Net, which allows us to better align facial features later to. We also separately obtain the mask of the mouth around the original video.
Then, we concatenate these and obtain new landmarks, which we pass into a network with encoded audio features to generate a low-resolution version of the lips. We enhance the mouth region using GPEN and GFPGAN, two generative face restoration algorithms, which allow the mouth and teeth to look more realistic, along with using Laplacian blending to seamlessly merge the newly generated mouth with the original video.
Video ReTalking on its own is pretty decent. However it can take up to a minute to generate a second of video, adds some unnecessary artifacts and blurriness in the video, and doesn’t handle certain edge cases properly, particularly when there are frames with no faces detected, the face is low resolution, or the face is close up.
Originally, we set out to improve the initial repository of Video ReTalking by:
- Smartly cropping around the face of the target speaker to avoid unnecessary processing on most of the video.
- Adding batching to the stabilization step, making this step much faster when combined with the cropping above.
- Removing the need to reinitialize the keypoint extractor multiple times to perform duplicate computations of landmarks during multiple steps of the process.
- Making the code more durable to edge cases where no faces are detected (by ignoring these frames), more than one face is detected (by detecting the largest face), or there is lots of movement from the speaker (by being smart about cropping).
- Optimizing memory and GPU memory throughout the code so that it can fit on an L4 GPU with 8 vCPUs and 32 GB RAM.
You can play with the improved version of Video Retalking here.
Recommendations
Ultimately, we believe SieveSync’s AI lip sync offering to be the most performant solution out there for developers looking to deploy a retalking model today. To try it, create an account or check out our explore page.