

Today, we’re announcing the beta release of Highlights — an app built to find key moments in long-form video content like podcasts, news shows, movies, and more using natural language search.
Creators currently use products like Descript, Grabyo, or Kick to stream and edit long-form content. However, much of their editing time is still spent on manually splitting their raw media into highlights or other bite-sized snippets.
Finding these highlights automatically with machine learning is quite challenging. Highlights can be very different between different types of content. In sports, a highlight might be defined as an action (like a goal or play) while in a podcast or stream, highlights relate more to the transcript. Building a good solution for highlight generation must include some flexibility on what type of content to filter for.
Our app allows users to search in natural language for “highlight terms” like “most interesting” or “most action” and receive a set of matching clips. Try it out on your own content here or integrate via API.
Let’s get into how we built it!
LLMs to navigate ambiguity
Video transcripts can be long and passing the entire transcript into the LLM to arbitrarily find highlights isn’t really useful given how ambiguous these definitions are. Below we discuss a more complex calling architecture that makes LLMs more useful for highlights.
Video as a discrete and ordinal time series
Our initial approach created a time series of “scores” where we passed each segment of the video’s transcript into a language model asking it to be scored from 1-100 depending on its relevance to the input “highlight phrase”.
For example, we may query for clips relating to “Artificial Intelligence.” Our transcript may include 2 segments: “The mitochondria is the powerhouse of the cell” and “The transformer architecture is at the heart of Language models,” both of which are compared to our query and assigned a relevance score.
Comparing each segment to our query generates a discrete time-series of relevance scores, which we can generate clips from.
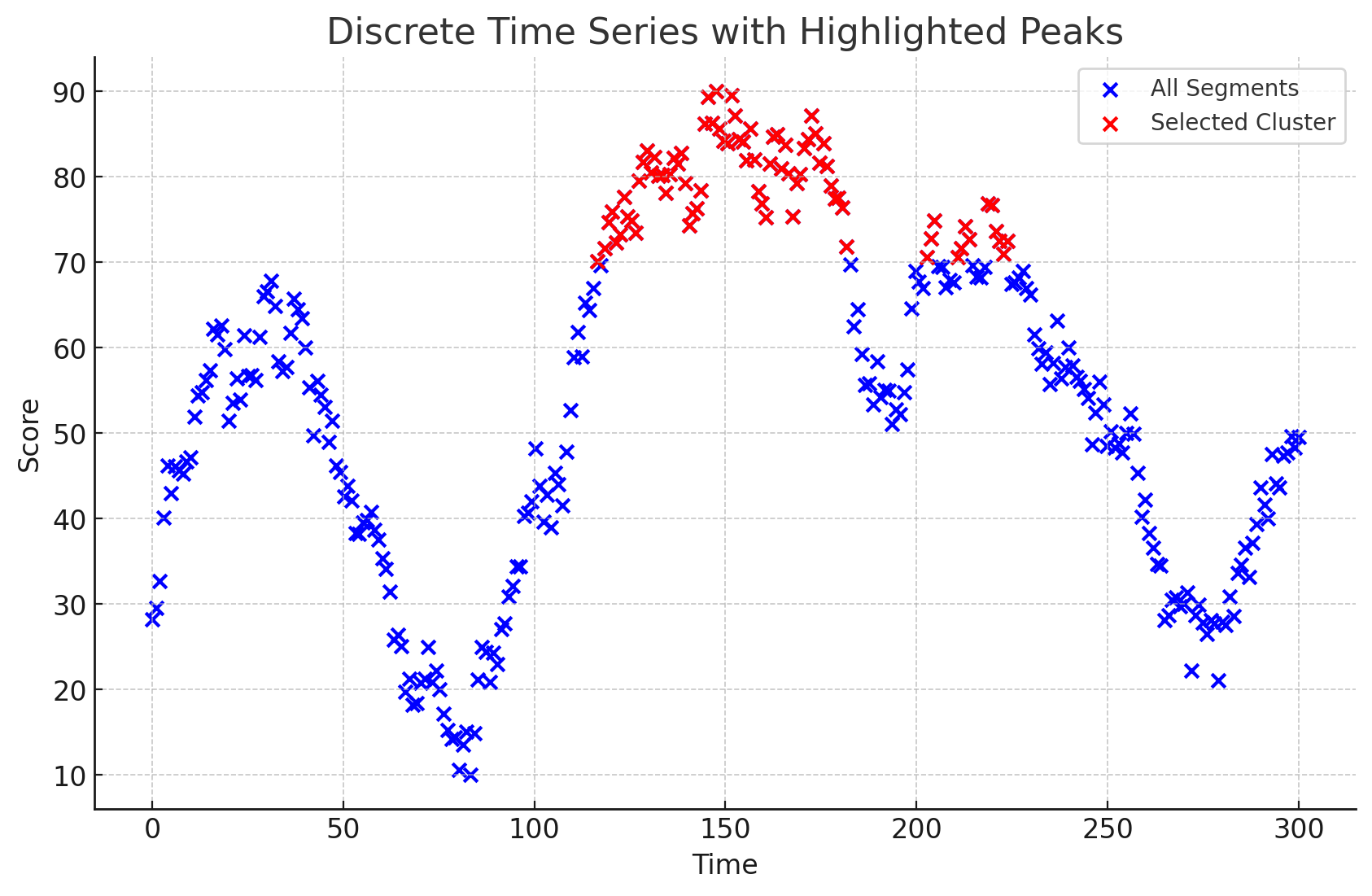
We then algorithmically extract peaks in relevance score using different event detection algorithms.
While this approach is sound in theory, it relies on the language model producing sensible outputs for the scores. Notably, we realize how language doesn’t always need to be the most “interesting” or “relevant” for it to be an important aspect of the output due to how many filler statements people tend to use like “that’s really cool” or “well done”. This makes us prone to poor scoring that can lead to many good highlights not being selected.
Giving the LLM better context
To overcome this issue in granular scoring, we can use language models for more parts of our pipeline. With any deep LLM prompting, we must balance long context lengths, which may lower granular understanding, and short context lengths which don’t provide enough information. Rather than scoring segments individually, we ask the language model to simply pick the highlights from a large batch of ordered segments while also reflecting on why it picked those sections.
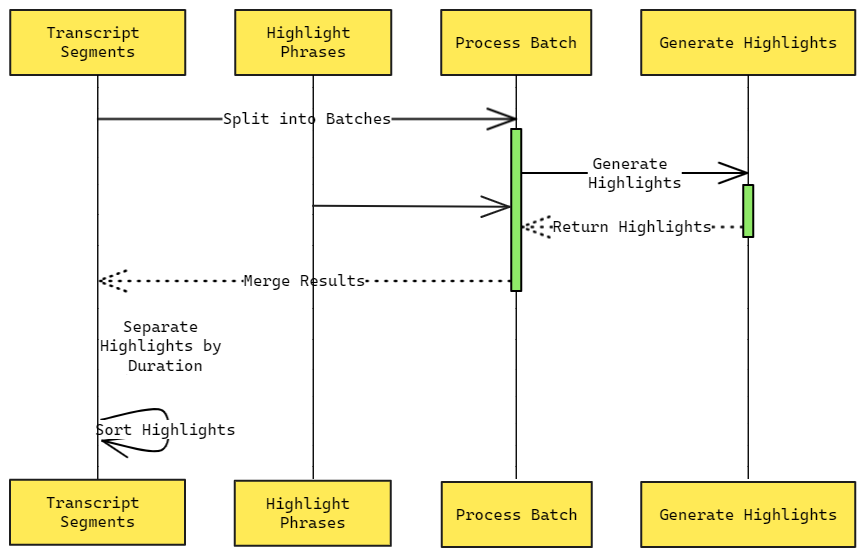
The cumulative segments can be broken down into batches of 500 where each segment is of length between 3-9 words and contains information like start and end timestamps.
So, worst case, we only pass about 10,000 tokens at a time - a fraction of the potential 128,000 context window of GPT4 and smaller than even most OSS LLMs (~16K token context windows). Our batch size can be decreased as needed as well.
Now, with some focused prompt engineering, we can extract information like start and end timestamps of the “highlights” along with a score for them between 0-100 based on their relevance to the user-entered “highlight phrases”.
PROMPT = """
You are a developer assistant where you only provide the code for a question. No explanation required. Write a simple json sample.
Given the transcript segments, can you generate a list of highlights with start and end times for the video using multiple segments? Please meet the following constraints:
Please meet the following constraints:
- The highlights should be a direct part of the video and should not be out of context
- The highlights should be interesting and clippable, providing value to the viewer
- The highlights should not be too short or too long, but should be just the right length to convey the information
- The highlights should include more than one segment to provide context and continuity
- The highlights should not cut off in the middle of a sentence or idea
- The user provided highlight phrases should be used to generate the highlights
- The highlights should be based on the relevance of the segments to the highlight phrases
- The highlights should be scored out of 100 based on the relevance of the segments to the highlight phrases
Respond with the following JSON schema for highlights:
{json_schema}
Each highlight should have the following fields:
- title: title of the highlight
- start_time: start time of the highlight as a float in seconds
- end_time: end time of the highlight as a float in seconds
- score: score of the highlight as a float out of 100
"""Notably, this gives the LLM the ability to reason about the broader “ideas” discussed in a set of segments rather than forcing it to score segments individually — which could be more arbitrary. We find this approach produces much higher quality outputs than before.
Improving transcription quality for better highlights
Given that transcription is core to generating good highlights, we use the speech transcriber readily available on Sieve for this use case.
import sieve
transcriber = sieve.function.get("sieve/speech_transcriber")
for segment in transcriber.run(
sieve.File(path=audio_path),
denoise_audio=True,
min_segment_length=60,
use_vad=True,
initial_prompt = "I made sure to add full capitalization and punctuation."
):
print(segment)Notably, we’re able to granularly parallelize and control how our audio is transcribed. In this case, we found the best results by denoising the audio, parallelizing transcription with minimum chunk lengths of 1 minute, and using voice activity detection to ensure parallelization only at the end of words spoken. We also found that forcing Whisper to add good punctuation throughout through prompts resulted in nicer segments to pass into GPT-4 later on.
Getting Started Yourself
The code for this is open-source and you can find it here. You can also try two different versions of this application on Sieve: one that renders the actual highlights into video clips for you and another that gives you more granular control over the parameters used for generating highlights.
If you have any thoughts or comments, please feel free to reach out to us by joining our Discord community. Excited to hear what you all think!