

Today, we’re announcing the beta release of Describe — a way to generate incredibly vivid descriptions of what happened in a given piece of video content. Below is an example ~2 min video that only cost ~$0.02 to process on Sieve’s starter plan.
In this video, a bald man in a black shirt is seen expressing intense frustration in a dimly lit room. Initially, he confronts someone named Elmer Fudd, questioning them about being out of tune and mockingly mentioning a Mars bar, directing the person's attention to himself. The situation escalates as the man criticizes another individual, Matt, for not admitting he was out of tune, accusing him of jeopardizing a competition due to lack of focus. He announces Matt's demotion and angrily demands him to leave. Surprisingly, the man clarifies that Matt wasn't out of tune; it was Erickson, criticizing Erickson's lack of awareness as equally grievous.
Describing videos automatically with machine learning models has always been challenging because of all the different things you need to take into account from the visuals, to the motion, spoken words, and background noises. However if it could be done well enough, it’d find immediate use across many areas such as media file search in products like Frame.io, better discoverability of content on sites like Khan Academy, more rich video collections on Google Photos, and much more.
The products I’ve listed above already have various forms of keyword search built in but it’s quite often limited to some metadata embedded in the file, or human-written description along with some text search.
VLMs and the power of sight
LLMs have had great success in being used to summarize text transcripts, ask questions about PDFs, and other related tasks. With the recent boom in MLLMs (Multimodal Large Language Models) and their fascinating ability to comprehend and interpret images, it feels like being able to do the same for video and audio is the natural next step.

Existing Approaches
Image-based
Image-based approaches rely on a single VLM inference to detail image specifics, a process that is direct but necessitates a potent VLM and some prompt engineering finesse. However, these strategies are constrained by the VLM's proficiency in managing intricate visuals and their inability to incorporate additional context or transcripts. Only a select few premium, proprietary VLMs such as Gemini, GPT4V, and Claude 3 possess the capability to process more context, but they come with high costs, slower video processing times, and still face limitations in context windows.
Transcript-based
Transcript-based approaches use a separate model for speech transcription, which is then processed by a language model. While these methods can generate rich summaries, they lack the ability to handle visual data, requiring careful pipeline design and prompt engineering to capture the essence of the video.
Cross-modal models
Cross-modal models like VideoLLaMa are recent attempts at bridging this gap between the different parts of a video, using a combination of image and audio embeddings. While approaches like these show promise in being a unified system with joint embedding space, these models struggle with bottlenecks in computation and input size. Any slightly complex scenario or long input and the performance degrades significantly. These approaches aren’t close to being production-ready and are extremely expensive.
Our Approach
Combining LLMs with decent context window sizes along with VLMs that have been demonstrated as powerful visual learners, we can construct an approach that allows both the visuals and the spoken content to operate at their fullest potential.
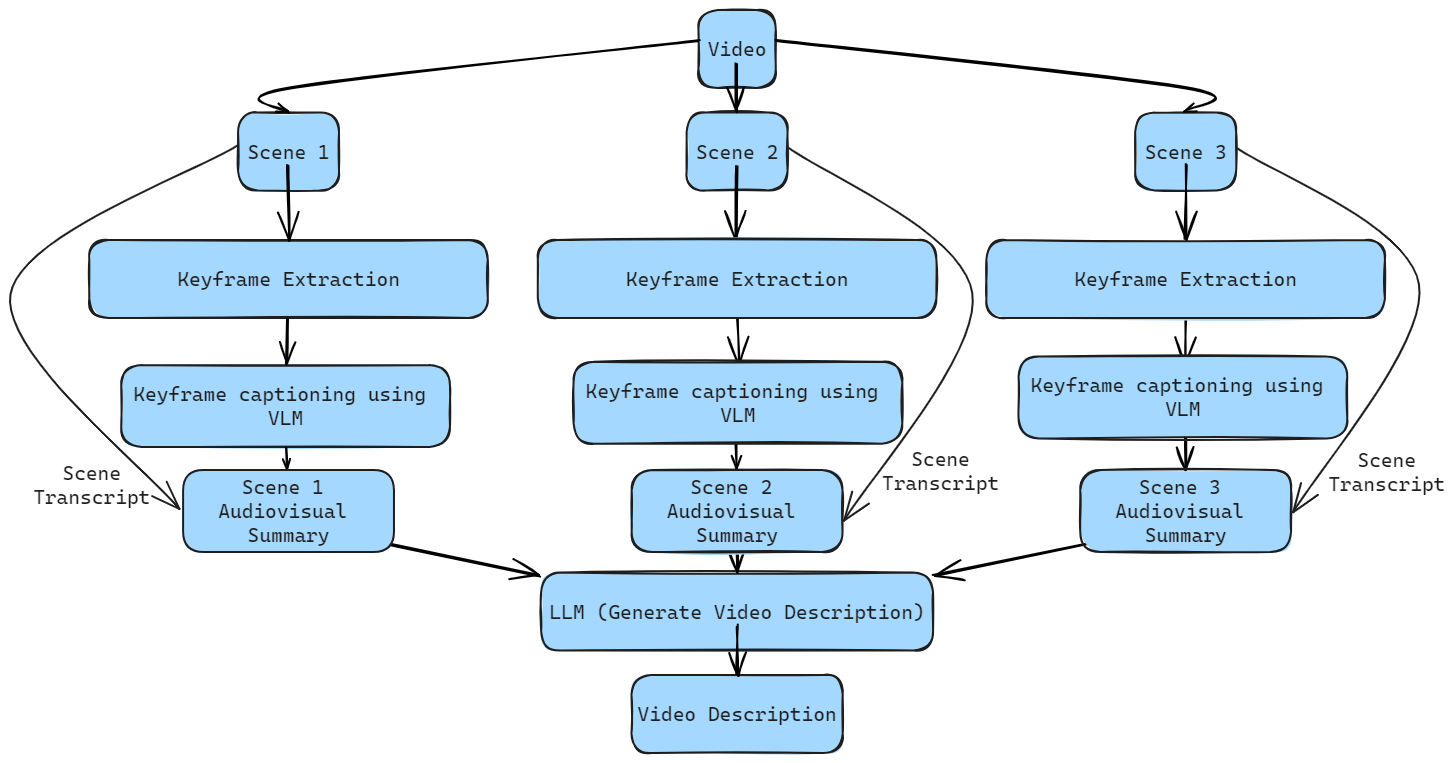
Here, we can see how a video gets broken down into its corresponding scenes (or chunks). Keyframes are then extracted from these chunks and processed to create a detailed visual caption - a task most VLMs excel at no matter their size.
These captions are then combined with the transcription of the respective scene extracted through Whisper, providing speech context as well. We now have multiple frames to encode the temporal nature of the video as well as how the “narrative” of the video has evolved across scenes - both in the highly detailed natural language. This natural language description of a scene can be constructed across the many scenes within a video, giving us numerous audiovisual descriptions of each “stage” of a video.
Finally, these descriptions can be combined into one, giving us a single, detailed audiovisual description of a video. At each “layer”, information loss is kept to a minimal by allowing both the LLM and VLM to perform tasks they inherently excel at like summarization and captioning. The extent of this information loss can be controlled via prompt engineering or choosing different sizes of models for different tradeoffs. Now, we have the ability to capture narrative nuance alongside key visual components.
Models used
We offer a suite of Video Language Models (VLMs) to balance between speed and performance. Moondream is a lightweight, fast and efficient VLM perfect for simpler visuals. InternLM-XComposer2 is mid-weight, offering detailed captions and fitting on a small GPU due to its quantization. CogVLM is a full-sized VLM, providing verbose and detailed captions for complex reasoning, albeit slower and more expensive. Users can choose the best setting based on their needs.
Implementation
Given that our approach combines multiple models together, Sieve’s infrastructure makes it really easy to implement with the benefit of parallelism — treating each of these models as if they were just python packages we were importing.
Running a VLM job on Sieve is like calling any other function.
import sieve
image = sieve.File(path="image.png")
question = "Describe this image."
moondream = sieve.function.get("sieve/moondream")
output = moondream.run(image, question)
print(output)After extracting keyframes from a scene, it takes only a few lines of code to push jobs to Sieve’s infrastructure in parallel.
import sieve
detail_prompt = "Describe this image with just the most important details. Be concise."
model_mapping = {"low": moondream, "medium": internlm, "high": cogvlm}
file_type = {"low": sieve.File, "medium": sieve.File, "high": sieve.Image}
captions = []
# for each keyframe that has been extracted and stored
for keyframe_path in keyframe_paths:
# check which level of detail the user would like
model = model_mapping[visual_detail]
# keep track of the file type
file_arg = file_type[visual_detail](path=keyframe_path)
# pass the job onto the Sieve infrastructure concurrently
keyframe_caption = model.push(file_arg, detail_prompt)
# append the 'Future' into the list and move on instead of waiting for completion
captions.append(keyframe_caption)
# store the results of each of the jobs that were pushed into a list
captions_list = [future.result() for future in captions_futures]Here, we see that we can go through a loop and push jobs to Sieve without waiting for them to complete and let them run in the background as we continue to process more keyframes. This way, we can process multiple scenes of a video at the same time making the processing times extremely low.
Getting Started Yourself
The code running on Sieve for this application is open-source and you can find it here. You can also try the app for yourself via the explore page or API by navigating here. The implementation on Sieve boasts efficiency and cost-reduction through methods like GPU sharing and increased throughput to each of the building blocks we’re using to build this application.
If you have any thoughts or comments, please feel free to reach out to us by joining our Discord community. Excited to see what folks build!