

In recent months, the demand for smaller and smaller AI models has continued to grow. Thanks to some clever tricks like quantization, better curated training data, synthetic data, and other smart tweaks, these models are shrinking in parameter size without losing their core capabilities. We’re excited about this because it means our customers can build more interactive features accessible to more of their users without bearing the expense of running large models.
Take moondream2 for example. It’s a tiny vision-language model that can run on devices as small as the Raspberry Pi. I asked it the following.
Question: What logo is on the player’s shirt and what is he doing?
Answer: Nike is on the player’s shirt, and they are walking into the stadium.

Pretty good! As models get smaller, they’ll get easier to run on the edge, but it also means you’ll need less resources to run them in the cloud.
At Sieve, we want to make it as easy as possible to discover, design, and run AI. A big part of that means running AI efficiently and so today, we’re excited to announce official support for GPU sharing on Sieve, with some of our public functions already making use of it.
What is it?
GPU time-sharing allows multiple containers to share a single physical GPU. This lets each container more efficiently use GPU resources to save running costs.
Time sharing works by allocating short time slices to different containers that share a single physical GPU in a round-robin fashion. More technically, the GPU context switches between all of the containers that are sharing the GPU. At any point in time, only one container can occupy the GPU. However, over a fixed time interval, the context switching ensures that each container gets the right proportion of the time-slice.
What is it useful for?
If you’re already seeing maximal utilization on a GPU, this feature isn’t really useful. However, most workloads aren’t like this. Many computer vision models, for example, perform CPU-intensive operations such as OpenCV preprocessing, video frame reading, and more, which are intertwined with the actual model's operation on a GPU. You could call these types of workloads “GPU bursty” since they are only using the GPU when they’re not doing the other pre or post processing steps.
Turning on GPU timesharing means that while your code may be doing some pre-processing, another process can be utilizing the GPU for a model operation at full speed. This makes timesharing especially useful for these sorts of “GPU bursty” workloads.
How is this different than Multi-Instance GPU (MIG)?
The latest NVIDIA GPUs have an operation mode called Multi-Instance GPU (MIG). NVIDIA’s docs compare MIG with time-sharing as follows:
MIG allows you to partition a GPU into several smaller, predefined instances, each of which looks like a mini-GPU that provides memory and fault isolation at the hardware layer. You can share access to a GPU by running workloads on one of these predefined instances instead of the full native GPU.
Time-slicing trades the memory and fault-isolation that is provided by MIG for the ability to share a GPU by a larger number of users. Time-slicing also provides a way to provide shared access to a GPU for older generation GPUs that do not support MIG. However, you can combine MIG and time-slicing to provide shared access to MIG instances.
On Sieve, we also offer the A100 20GB compute type, which is an A100 using the MIG operation mode. You can choose to further slice this with timesharing if you’d like maximal utilization along with hardware guarantees.
Sample Benchmark
Let’s run a benchmark with the video-retalking model, an AI model that performs relatively high quality lipsync. The interesting thing about this repository is that it’s actually a combination of models that detect face landmarks, perform varying image transformation, generate lips, upscale images, and more, to then generate the output video.
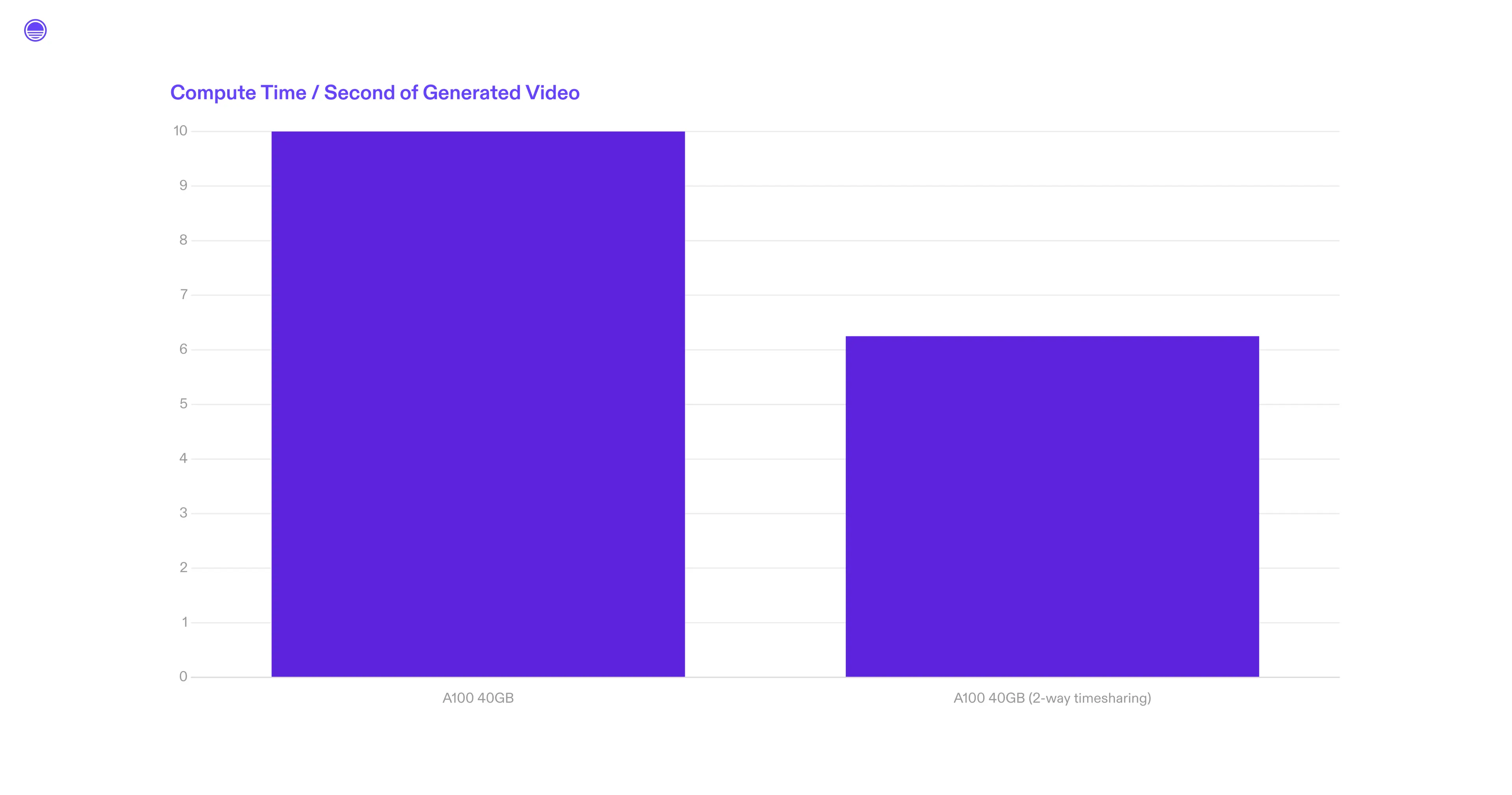
We optimized this model and used to run it on an A100 40GB GPU, which would take ~10 seconds to generate a single second of video. This was already much faster than the original repository, which would takes 60s to generate a single second of video (read more about our work here!).
We recently moved this model to run on an A100 with GPU time-sharing set to a split of 2. Previously, the model would use the whole GPU for 10 seconds to generate a single second of video. With time-sharing enabled, the model now uses half the A100 to generate a single second of video in 12.5 seconds. While the individual generation is slower, two generations can now run concurrently.
What used to be 10 seconds of A100 compute time for 1 second of generated video is now 12.5 seconds of compute time for 2 seconds of generated video. That’s almost a 40% efficiency gain with no other code changes!
How do I use it?
If you’re using public functions on Sieve, we’re slowly transitioning various functions to leverage GPU sharing. YOLO, for example, splits a T4 two ways, XTTS splits an A100 4 ways, TalkNet splits an L4 3 ways, and Video Retalking splits an A100 two ways now. This generally means greater throughput and lower cost for these functions.
If you’re deploying custom functions on Sieve, enable time-sharing is as simple as adding a split option to your decorator.
@sieve.function(
name="gpu_function_sharing",
gpu=sieve.gpu.T4(split=3)
)
def runs_on_gpu(video: sieve.File) -> sieve.File:
...If no split is specified, the GPU will be used regularly without time sharing. Read more about it in our docs.
Conclusion
A core belief we have at Sieve is the idea that combining many models together makes building useful AI apps easier and faster. With GPU sharing, it means each of these models will naturally become even faster and more cost-effective.
We’ve already seen this feature magically speed up certain customer workloads and we’re excited to see what you build with the gain in efficiency :)