NEW
Dubbing 3.0 is hereSmarter translations, cleaner audio, and more natural multi-speaker dubbing.Try it now
The highest quality, most flexible dubbing solution
Translate video and audio content with best-in-class quality, control, and scale.






Sieve’s dubbing API just worked—super easy to plug in, and the quality blew everything else we tested out of the water. It gave us the flexibility to build an interactive, editable experience that actually scales with our users and adapts as they go.

Timur Mamedov, CTO
Best-in-class quality
Human-preferred
We benchmarked Sieve's dubbing solution with real humans who preferred Sieve's outputs on vectors such as linguistics, speech, timing, lipsync, background noise, and multi-speaker handling.

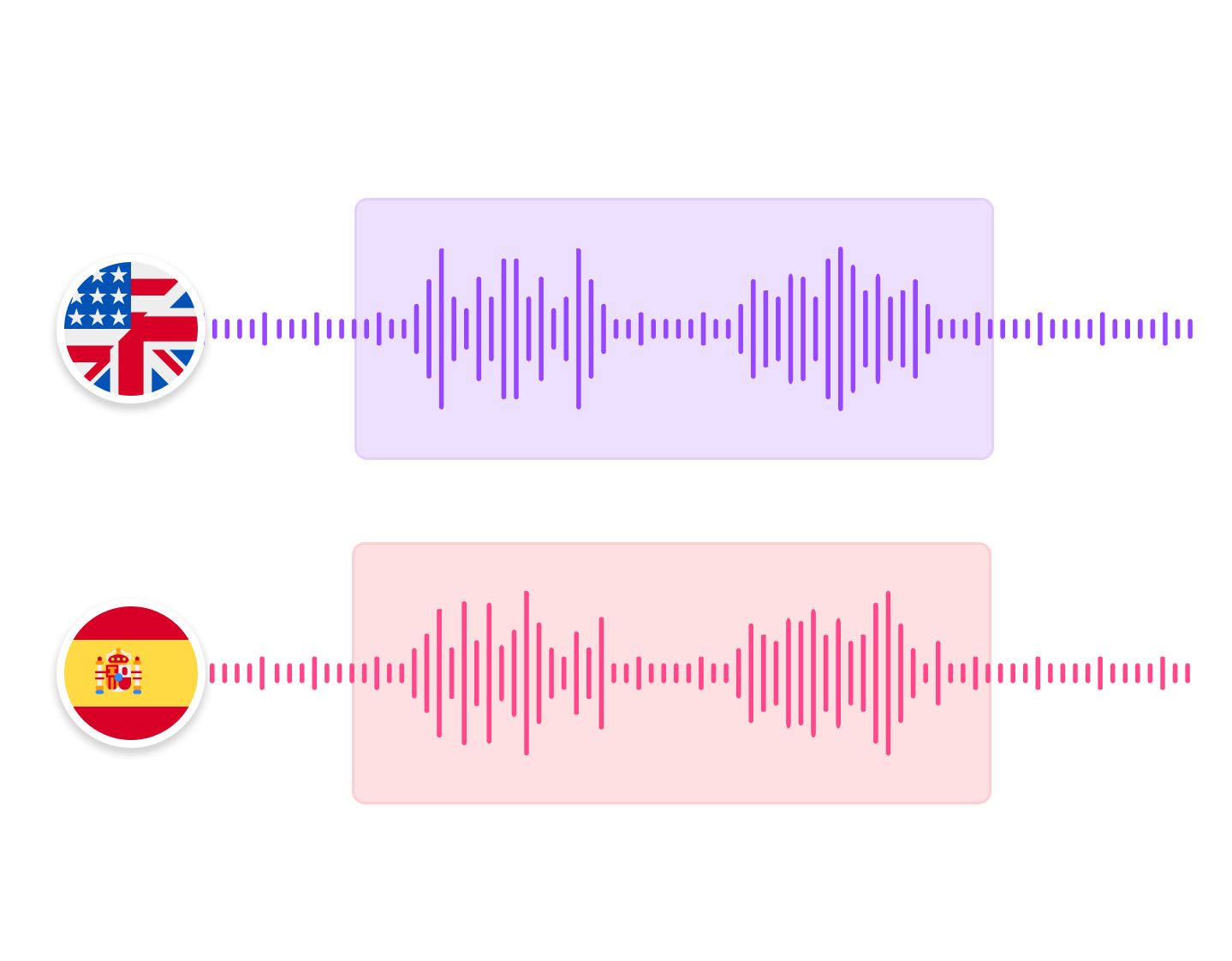
High quality voice preservation
Maintain original speaker speaker voice and style — even in dynamic settings with noisy audio, multiple speakers, etc.

Phrase-perfect timing
Keep the timing of every phrase in sync with source media through state-of-the-art audio length & phoneme prediction.
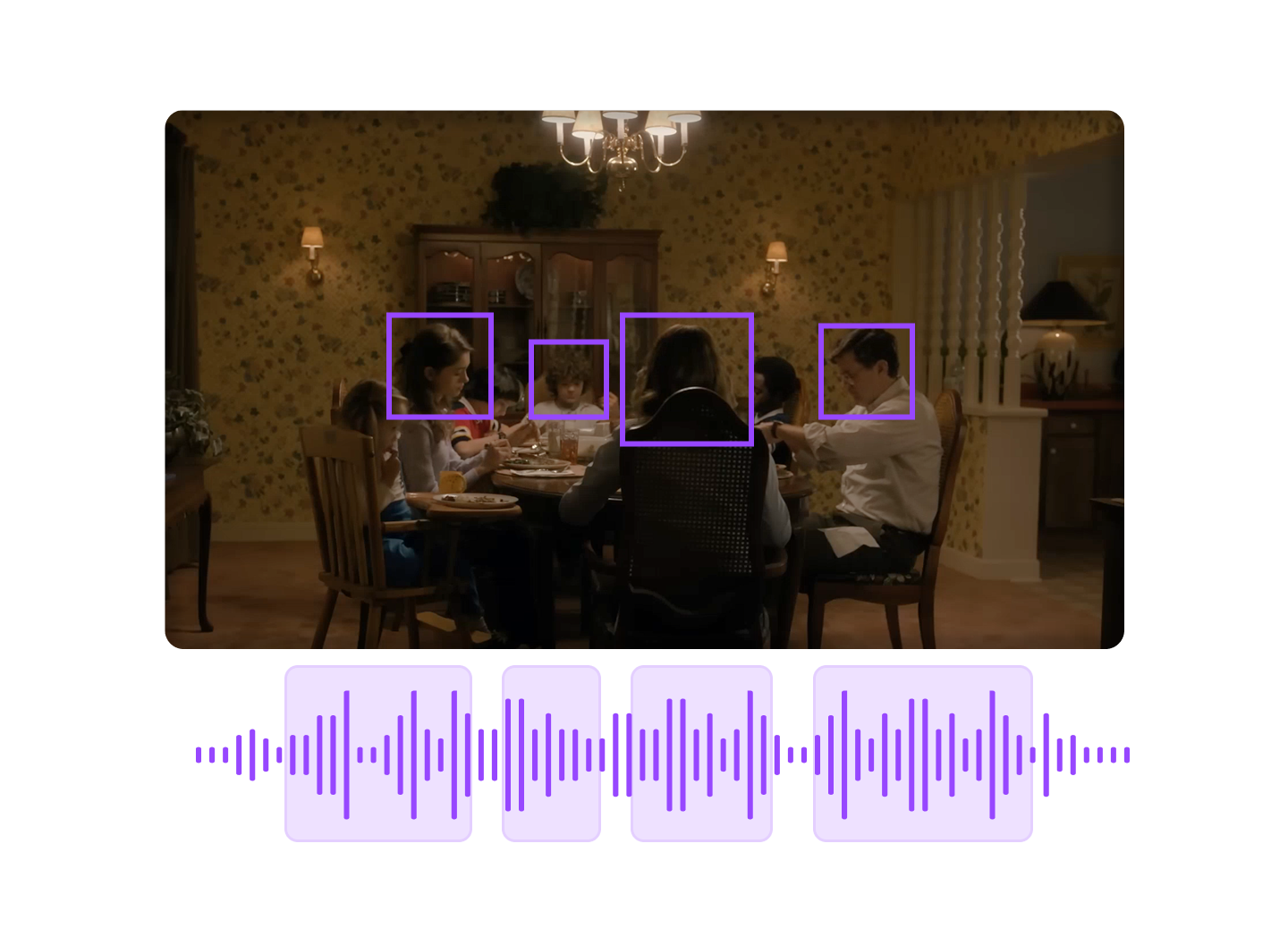
Multi-speaker segmentation
Accurately chunk, translate, and dub audio by individual speaker using diarization powered by our large joint audio-language model.
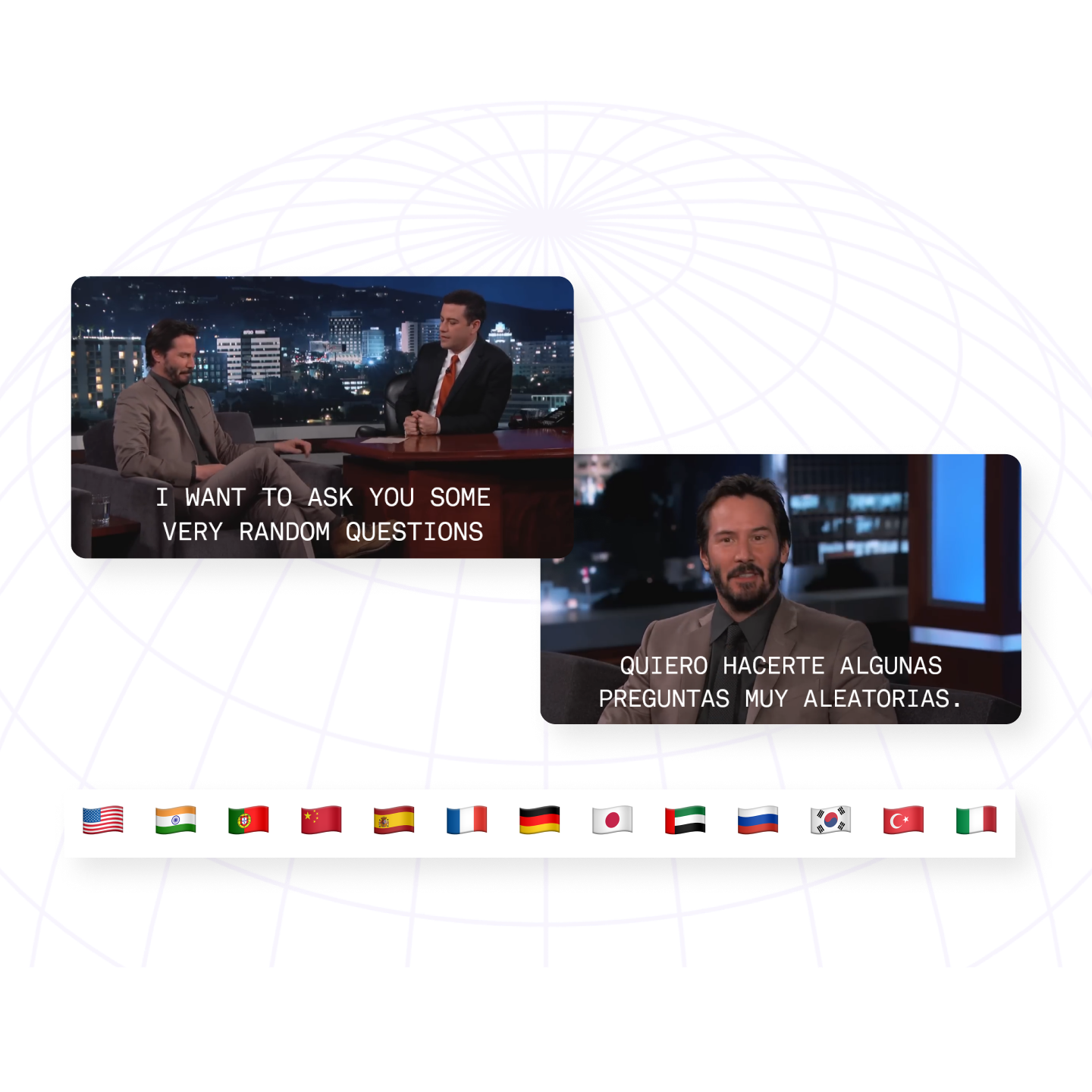
World-class, no-training lipsync
Sync the generated audio to lip movements of original speakers with high fidelity, even in diverse environments.
Maximum flexibility & control
Translation styling
Pick specific styles like 'Brazilian Portuguese' or 'Informal Spanish' to bias translations to specific regions.
Safe words
Select words (brand names, slogans, etc) that shouldn't be translated.
Translation dictionary
Map specific key words or phrases to be translated in a specific way.
Custom transcripts
Pass in custom transcripts or translations to override AI processing.
Review and edit
Select between voice dubbing or translation only outputs modes to create human-in-the-loop review and editing flows.
Backend engines
Pick between various voice, language, and audio engines based on your needs.
Translation styling
Pick specific styles like 'Brazilian Portuguese' or 'Informal Spanish' to bias translations to specific regions.
Safe words
Select words (brand names, slogans, etc) that shouldn't be translated.
Translation dictionary
Map specific key words or phrases to be translated in a specific way.
Custom transcripts
Pass in custom transcripts or translations to override AI processing.
Review and edit
Select between voice dubbing or translation only outputs modes to create human-in-the-loop review and editing flows.
Backend engines
Pick between various voice, language, and audio engines based on your needs.
Built for scale
Enterprise SLAs
Uptime & processing SLAs for ad-hoc, large batch, and production use cases.
Dedicated support
Tailored onboarding, customization, and support from our team.
Volume discounts
Significant discounts that enable enterprise scale.
Scalable API
Built to process millions of hours of video at any given moment.

Secure
End-to-end encryption, custom data retention, and SOC 2 Type 2 secured.

Frequently Asked Questions
How many languages are supported?
32 when voice cloning is enabled and 100+ with a non-cloning based voice engine.
Can Sieve preserve the original speakers voice?
Yes, the default voice engine supports speaker voice preservation.
What if there are multiple speakers?
Sieve automatically handles multi-speaker videos through high quality segmenting and diarization.
Are outputs editable?
Yes, you can use the `edit_segments` parameter to override transcription or translations.
Does Sieve train on my inputs or data?
No, never.
How can I start dubbing with Sieve?
You can try it out in our playground linked here.
Is real-time supported?
No, not at the moment.