NEW
Dubbing 3.0 is hereSmarter translations, cleaner audio, and more natural multi-speaker dubbing.Try it now
The all-in-one lipsync solution
Production-grade models & complementary tooling for syncing lip movements in any video to match audio input.





High quality is non-negotiable for us. What really blew us away about Sieve’s lipsync API is the flexibility to route different product flows through different backends which is a total game changer in terms of managing costs and user experience all while ensuring high quality.

Brandon Escalante, CPO
Best-in-class quality
A variety of models in one place
A single interface to the best lipsyncing models in the world so you can pick the quality/speed/cost that suits your needs.
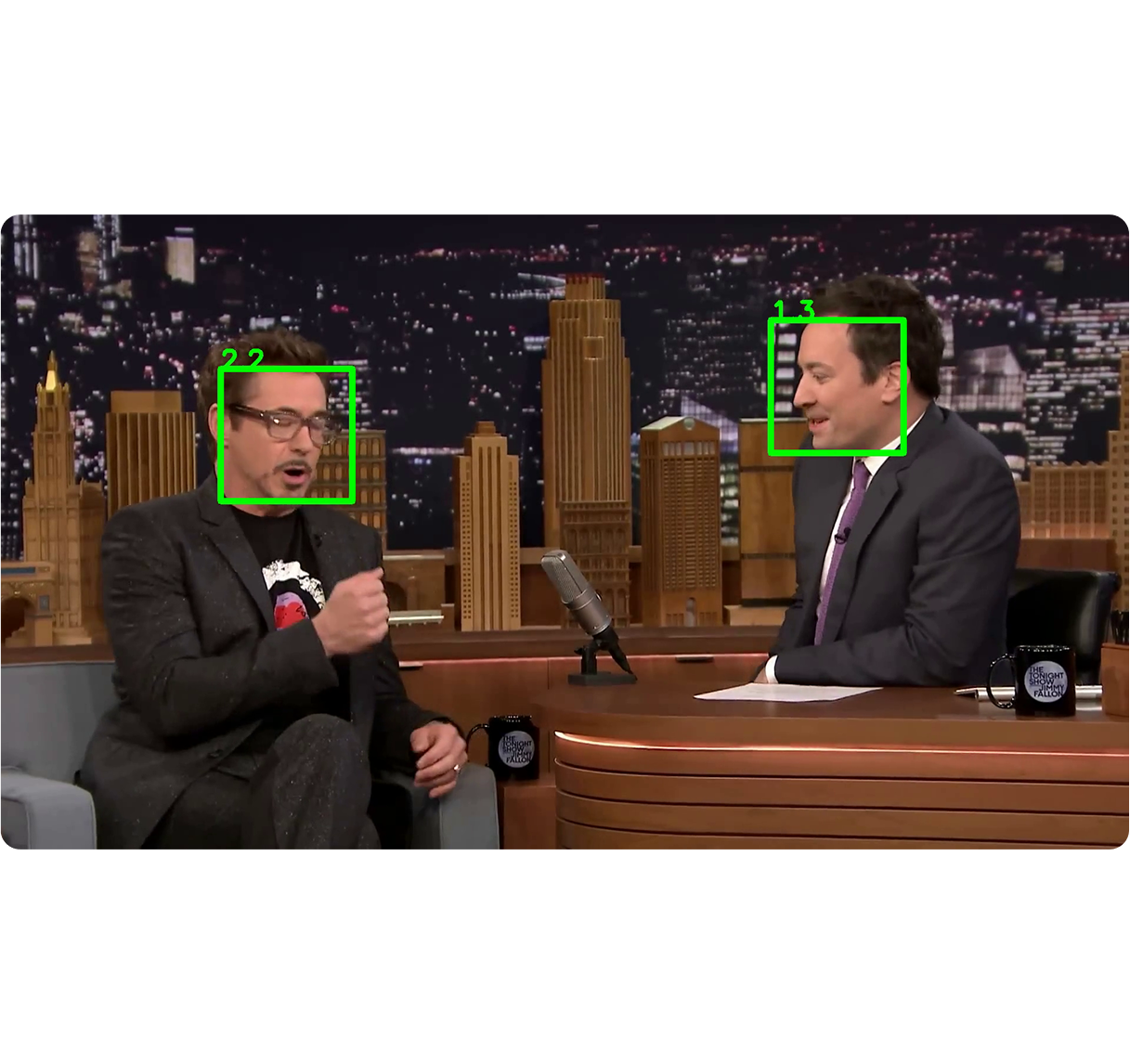
Multi-speaker support
Lipsync videos with multiple speakers automatically through automatic speaker recognition and tracking.
Hallucination safeguards
AI quality checking that prevents malformed outputs from ever reaching the eyes of end users and audiences.

Enhancement options
Further enhance model rendering outputs through AI upscaling.

Built for scale
Enterprise SLAs
Uptime & processing SLAs for ad-hoc, large batch, and production use cases.
Dedicated support
Tailored onboarding, customization, and support from our team.
Volume discounts
Significant discounts that enable enterprise scale.
Scalable API
Built to process millions of hours of video at any given moment.

Secure
End-to-end encryption, custom data retention, and SOC 2 Type 2 secured.

Frequently Asked Questions
What type of videos work best for lipsyncing?
Videos with clear, front-facing human subjects and consistent speech ("talking head" video, interviews, vlogs, etc). For best results, avoid fast cuts, face obstructions, or extreme head movements.
Does Sieve's lipsyncing require training?
Unlike most other providers who require 2-3 minutes of "training" video, Sieve offers a training-free approach. Simply upload your video and target audio & Sieve will handle the rest.
How often does Sieve incorporate the newest underlying models?
We regularly incorporate the latest & best available models - keeping up with the SoTA so you don't have to.
What if I want to do both dubbing & lipsyncing?
You can also run Lipsync directly within our Dubbing function! Simply select "enable_lipsyncing".
Is real-time supported?
No, not at the moment.
How can I start lipsyncing with Sieve?
You can try it out in our playground.
Is faster processing available?
Faster processing is available as part of our Production Tier.
Are discounts available?
Discounts are available as part of our Production Tier.
Does Sieve train on my inputs or data?
No, never.